
Publications
You can also find my articles on my Google Scholar Profile.Show selected / Show all by date / Show all by topic
 | Robot Parkour Learning Ziwen Zhuang*, Zipeng Fu*, Jianren Wang, Christopher Atkeson, Soren Schwertfeger, Chelsea Finn, Hang Zhao 2023 Conference on Robot Learning (Best Systems Paper Finalist) [Project Page] [Code] [Abstract] [Bibtex] Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
@article{zhuang2023parkour,
title={Robot Parkour Learning},
author={Zhuang, Ziwen and Fu, Zipeng and Wang, Jianren and Atkeson, Christopher and Schwertfeger, Soren and Finn, Chelsea and Zhao, Hang},
journal={CoRL},
year={2023}
}
|
 | Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations Jianren Wang*, Sudeep Dasari*, Mohan Kumar, Shubham Tulsiani, Abhinav Gupta (* indicates equal contribution) 2023 International Conference on Computer Vision (Oral) [Project Page] [Code] [Abstract] [Bibtex] The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as \textit{distances} (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time.
@article{wang2023manipulate,
title={Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations},
author={Wang, Jianren and Dasari, Sudeep and Srirama, Mohan Kumar and Tulsiani, Shubham and Gupta, Abhinav},
journal={ICCV},
year={2023}
}
|
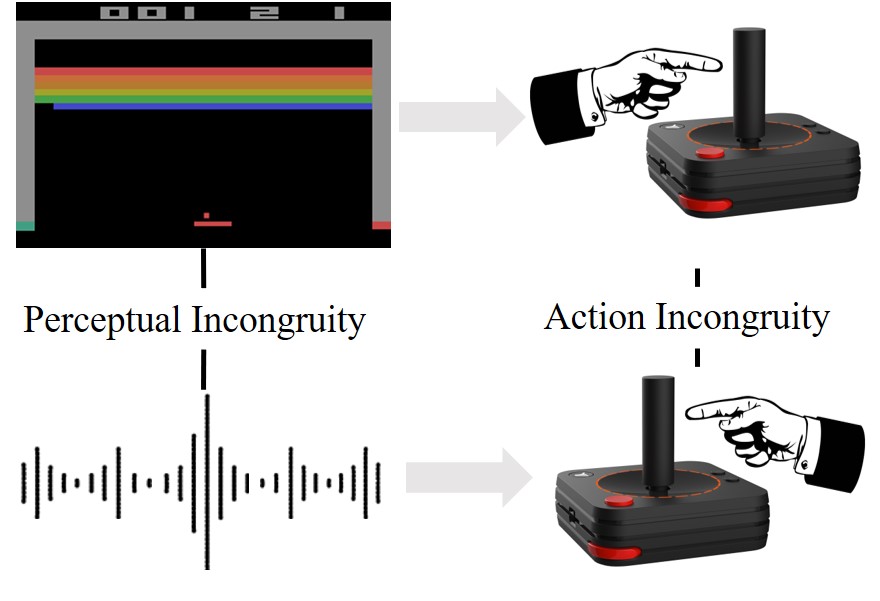 | SEMI: Self-supervised Exploration via Multisensory Incongruity Jianren Wang*, Ziwen Zhuang*, Hang Zhao (* indicates equal contribution) 2022 IEEE International Conference on Robotics and Automation [Project Page] [Code] [Abstract] [Bibtex] Efficient exploration is a long-standing problem in reinforcement learning since extrinsic rewards are usually sparse or missing. A popular solution to this issue is to feed an agent with novelty signals as intrinsic rewards. In this work, we introduce SEMI, a self-supervised exploration policy by incentivizing the agent to maximize a new novelty signal: multisensory incongruity, which can be measured in two aspects, perception incongruity and action incongruity. The former represents the misalignment of the multisensory inputs, while the latter represents the variance of an agent's policies under different sensory inputs. Specifically, an alignment predictor is learned to detect whether multiple sensory inputs are aligned, the error of which is used to measure perception incongruity. A policy model takes different combinations of the multisensory observations as input, and outputs actions for exploration. The variance of actions is further used to measure action incongruity. Using both incongruities as intrinsic rewards, SEMI allows an agent to learn skills by exploring in a self-supervised manner without any external rewards. We further show that SEMI is compatible with extrinsic rewards and it improves sample efficiency of policy learning. The effectiveness of SEMI is demonstrated across a variety of benchmark environments including object manipulation and audio-visual games.
@article{wang2022semi,
title={SEMI: Self-supervised Exploration via Multisensory Incongruity},
author={Wang, Jianren and Zhuang, Ziwen and Zhao, Hang},
journal={IEEE International Conference on Robotics and Automation},
year={2022}
}
|
 | Wanderlust: Online Continual Object Detection in the Real World Jianren Wang, Xin Wang, Yue Shang-Guan, Abhinav Gupta 2021 International Conference on Computer Vision [Project Page] [Code] [Abstract] [Bibtex] Online continual learning from data streams in dynamic environments is a critical direction in the computer vision field. However, realistic benchmarks and fundamental studies in this line are still missing. To bridge the gap, we present a new online continual object detection benchmark with an egocentric video dataset, Objects Around Krishna (OAK). OAK adopts the KrishnaCAM videos, an ego-centric video stream collected over nine months by a graduate student. OAK provides exhaustive bounding box annotations of 80 video snippets (~17.5 hours) for 105 object categories in outdoor scenes. The emergence of new object categories in our benchmark follows a pattern similar to what a single person might see in their day-to-day life. The dataset also captures the natural distribution shifts as the person travels to different places. These egocentric long running videos provide a realistic playground for continual learning algorithms, especially in online embodied settings. We also introduce new evaluation metrics to evaluate the model performance and catastrophic forgetting and provide baseline studies for online continual object detection. We believe this benchmark will pose new exciting challenges for learning from non-stationary data in continual learning.
@article{wang2021wanderlust,
title={Wanderlust: Online Continual Object Detection in the Real World},
author={Wang, Jianren and Wang, Xin and Shang-Guan, Yue and Gupta, Abhinav},
journal={ICCV},
year={2021}
}
|